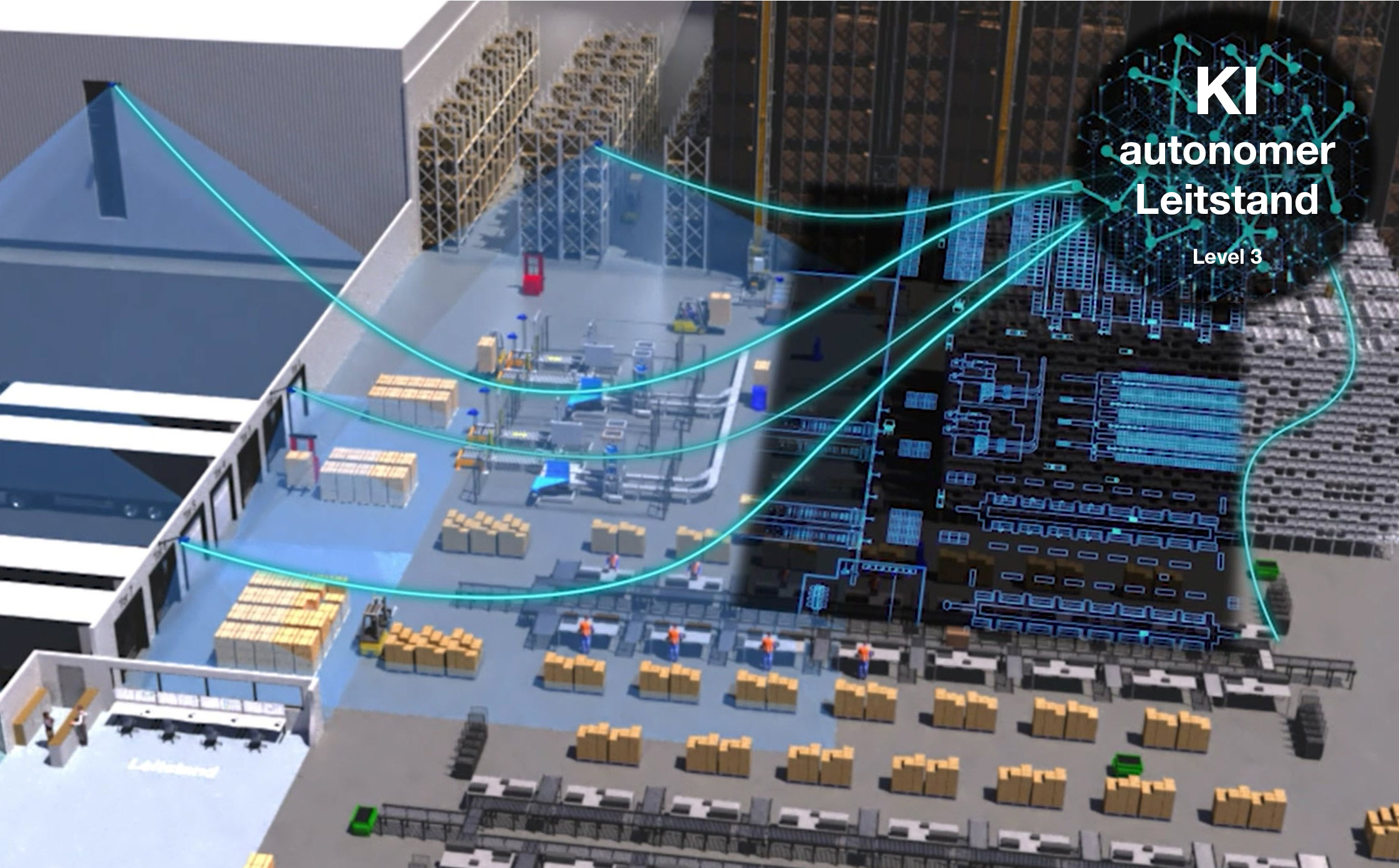
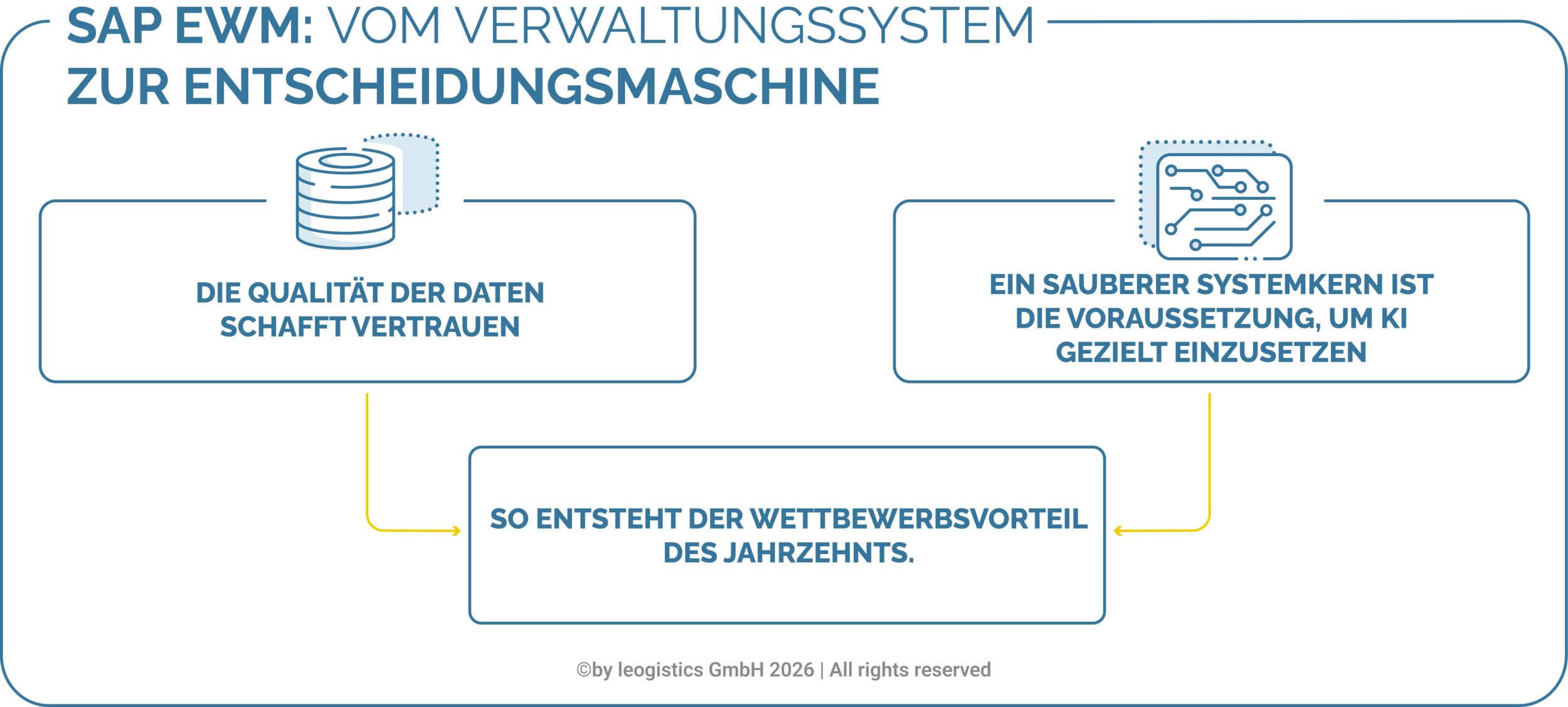
Die Intralogistik könnte man als eine Paradedisziplin für Künstliche Intelligenz (KI) bezeichnen. Autonome Transportsysteme, Predictive Maintenance, mehrsprachiges Pick-by-Voice, KI-gestützte Fahrerüberwachung bei Flurförderzeugen – die Liste an Einsatzmöglichkeiten ist fast beliebig erweiterbar. Die KI wertet dabei Daten, etwa von Scannern und Sensoren, aus und entwickelt daraus Muster, Prognosen und sogar Entscheidungen. Je größer die Datenmenge, umso besser für das Training der hinterlegten Algorithmen.
Personenbezogene Daten
Das ruft unweigerlich den Datenschutz auf den Plan. Zwar stärkt der EU-Gesetzgeber jetzt den Datenverkehr unter anderem durch den neuen Data Act, der für einen freien Datenzugang und eine faire Datennutzung sorgen soll. Das gibt etwa dem Käufer und Nutzer einer Automationskomponente, wie sie in einem smarten Lager verbaut ist, mehr Rechte im Hinblick auf die Nutzung der Daten, die dort anfallen. Aber es entlastet ihn nicht davon, mit diesem Schatz besonders sorgsam umzugehen, sobald ein Bezug zu Personen herstellbar ist. Denn dann gilt auch für KI-generierte Daten die Datenschutz-Grundverordnung (DS-GVO) mit ihren Anforderungen an Datenminimierung, Transparenz und Zweckbindung.
Beschäftigtendatenschutz
Und der Personenbezug ist schnell hergestellt. So ist die Fehlerauslesung einer Maschine zunächst ein rein industrieller Datensatz. Wenn aber anhand weiterer generierter Informationen Rückschlüsse auf einzelne Personen wie Maschinenführer oder Wartungspersonal möglich sind, werden daraus personenbezogene Daten. Dieser Maschinenführer hat dann aufgrund des Beschäftigtendatenschutzes ein Recht darauf, vom Arbeitgeber über die Verarbeitungszwecke und -auswirkungen informiert zu werden – und auch über die dahinterstehende KI-Logik, die mit „seinen“ Daten trainiert und arbeitet. Mit einer hängenden Beschilderung über 18.000 Stellplätzen hat ONK den Boden für die Digitalisierung im Lager von Feldsaaten Freudenberger bereitet. ‣ weiterlesen
Flexibilität hängt oben
Problem: Zweckänderung
Problematisch ist, wenn sich dieser Zweck ändert und die KI das Datenmaterial für weitere Zwecke verwendet, die bei Erhebung noch gar nicht absehbar waren. Die rasante technische Entwicklung und zunehmende Autonomie der lernenden Systeme machen ein solches Szenario möglich. In diesem Fall sind Zweck, Dauer und Auswirkungen für den Arbeitgeber besonders schwer einzugrenzen, und eine Verletzung des Beschäftigtendatenschutzes droht.
Zwar sollen laut dem neuen KI-Gesetz der Europäischen Union, über das man sich wohl im Februar 2024 endgültig einigen wird, insbesondere KI-Systeme mit hohem Risiko so konzipiert sein, dass ihr Betrieb hinreichend transparent ist und Nutzer die Ergebnisse des Systems angemessen interpretieren und verwenden können. Das adressiert aber nur den Entwickler und schützt den Nutzer, der KI in seinem Betrieb konkret einsetzt, nicht davor, wegen Datenschutzverstößen mit Bußgeldern nach der DS-GVO belegt zu werden.
Sicherheit durch Anonymisierung
Entweder muss also gewährleistet und dokumentiert sein, dass eine KI wirklich nur rein industrielle Daten nutzt. Oder man geht den sicheren Weg über die Anonymisierung aller Daten, und zwar am besten bereits in der Speicherumgebung der Rohdaten, also vor der Übertragung in die KI-Umgebung. Fest steht: Der Datenschutz „erledigt“ sich nicht durch KI-Gesetz und EU-Data-Acts, sondern verfestigt sich als übergeordnete Aufgabe.